Motivation
This three-part series delves into fine-tuning and deploying Large Language Models (LLMs) efficiently and economically. Practical strategies will be shared, enabling you to harness the immense capabilities of these models without breaking the bank.
Companies employ LLMs for varied purposes. Some extract structured insights like sentiments or summaries from vast texts. Others integrate LLMs within chat interfaces, facilitating enhanced customer service, language applications, or even just general chit-chat. Take, for instance, ChatGPT by OpenAI. This general-purpose interface allows users to seek answers on diverse topics, ranging from holiday destinations to crafting PowerPoint slides for a critical management presentation. Moreover, OpenAI offers their expertise through APIs, allowing seamless integration of the model into a myriad of tasks.
A Costly Conundrum with Off-the-Shelf Models
Imagine running a company that offers structured analysis on consumer texts. Your task? Mine millions of texts to distill insights such as sentiments, summaries, or highlighted aspects, and subsequently sell this invaluable analysis back to the firms whose reviews you’ve scrutinized.
At the outset, OpenAI’s GPT-3.5 seems like the golden ticket. Its impressive capabilities appear tailor-made for such a task. But here’s the rub: every API call to GPT-3.5 comes with a hefty price tag. Crunch the numbers, and a startling picture emerges — the costs spiral beyond your earnings. Now, you’re caught in a fiscal bind. What should be a profitable venture becomes a drain on resources.
As an ML Engineer, the challenge is twofold: drive down expenses without compromising on performance. An initial thought might be to pivot towards open-source LLMs. Consider using models like llama by META or falcon. The allure of these models is undeniable — they’re free to use. However, this freedom comes with its own set of caveats. Deploying these behemoth models requires substantial GPU resources, and the associated costs can skyrocket.
You might be tempted to streamline deployment through quantization, hoping for a leaner, more cost-effective model. Yet, there’s a catch. These quantized models, while smaller, often don’t measure up to the performance standards set by GPT-3.5 from OpenAI. Complicating matters further, the exact implementation nuances of OpenAI’s model remain shrouded in mystery.
In summary, The challenge is clear and dual-faceted: we need a model that’s both cost-effective to deploy and proficient for our specific use-case. The solution? A strategic blend of fine-tuning paired with quantized deployment.
Finetuning and Quantized Deployment: A Primer
Stepping into the world of machine learning models, one quickly realizes the delicate balance between cost and performance. For instance, take the challenge of harnessing open-source models. The initial thrill of accessing them for free is often dampened by the realization of deployment costs. Deploying these behemoths necessitates substantial GPU infrastructure. Add to this, a discovery: these models, when trimmed using quantization, often lag behind the performance set by proprietary models like OpenAI’s GPT-3.5.
Solution? We approach this in two strategic steps:
- Condense the model size.
- Fine-tune only a select portion of the model using specific datasets.
By the end of this series, we’ll explore how QLoRA masterfully integrates both steps, paving the way for cost-efficient fine-tuning and deployment of Large Language Models. And for those keen on practical implementation, a comprehensive notebook detailing the fine-tuning and deployment using QLoRA will be shared. But for now, let’s shift our focus to the ‘LoRA’ component of QLoRA and its prowess in parameter-efficient tuning.
LoRA: A Deeper Dive
Recent advancements have birthed models staggering in size, boasting hundreds of billions of parameters. Training such colossi requires intense computational firepower. In the golden days, when models housed merely millions of parameters, full-model fine-tuning was plausible. Today, with parameters in billions, it’s a different ballgame.
Enter LoRA
At its core, LoRA introduces new parameters, training only these newcomers while leaving the original parameters untouched. The magic? Even though the original parameters are static, they play a crucial role in both the forward and backward passes, crucially influencing the updated parameters.
Under The Hood
All models can be envisioned as an intricate web of matrices powered by a computation graph. Given an input $X$ the model undertakes a series of operations, eventually delivering the output. The heart of training revolves around refining the matrices, denoted as $W$ to yield desired outputs.
LoRA’s genius lies in tweaking model parameters. Consider a change $\Delta W$ to our original $W$. The objective? Arrive at a new parameter set $W_{new} = W + \Delta W$. Instead of manipulating $W$ directly to determine $\Delta W$, LoRA proposes a clever workaround: factorize $\Delta W$ into two lower-rank matrices, $A$ and $B$. If $W$ is a (100 x 100) matrix and both $A$ and $B$ are dimensioned at (100 x k) (with k <100), $\Delta W$ can be effectively represented by the product $A$ x $B$.
The brilliance of this strategy is evident when we assess its computational efficiency. For a $W$ matrix with 10,000 parameters, using LoRA with k=2 results in a staggering reduction to just 200 parameters!
LoRA’s Strengths
- Memory Efficiency During Training:
- Gradients: In traditional fine-tuning, for every trainable parameter, a gradient needs to be computed and stored during backpropagation. This effectively doubles the memory required per parameter. By having a lower number of trainable parameters with LoRA, the memory used for storing gradients is significantly reduced.
- Optimizer States: Optimizers like Adam store additional information for each trainable parameter, such as moving averages of past gradients. This adds another layer of memory requirement for each trainable parameter. With LoRA’s reduced trainable parameter count, the memory overhead from the optimizer states is also substantially decreased.
- Speeding Up Training:
- Fewer trainable parameters mean faster parameter updates during each iteration of training. With a reduced parameter count, backpropagation is quicker, leading to faster epoch times and overall training duration.
- Mitigating Overfitting:
- When fine-tuning very large models on small downstream datasets, there’s a risk of overfitting. By reducing the number of parameters that get adjusted during fine-tuning, LoRA reduces the model’s capacity to overfit to the smaller dataset.
- Scalability and Versatility:
- LoRA provides a scalable approach to adapt large models across various tasks without the need to maintain separate, fully fine-tuned instances of the model for each task.
LoRA’s Weaknesses
- Initial Model Weight Memory Requirement:
- Regardless of the reduction in trainable parameters, the initial, large, pre-trained model weights still need to be loaded into memory. For extremely large models, these weights alone can exceed the memory of a single GPU. LoRA doesn’t mitigate this aspect, and techniques like model parallelism or multi-GPU setups would still be needed to handle these massive models.
- Activations Memory During Training:
- LoRA focuses on reducing the trainable parameter count, but during the forward and backward passes, the model still produces and stores activations for each layer. Especially for deep models, these activations can consume substantial memory, and LoRA doesn’t directly address this memory usage.
- Deployment Size of the Model:
- While LoRA makes the training process more efficient, the size of the model for deployment remains largely the same since the majority of the weights are frozen and retained. If there are constraints on model deployment size (for edge devices, mobile, etc.), LoRA doesn’t provide a solution for that.
LoRA Forward Pass
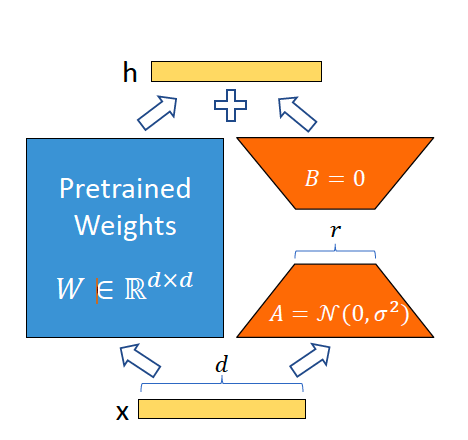
Source: original paper
In traditional setups, a forward pass for a given input $x$ and model weights $W$ was straightforward:
$h = Wx$
Enter LoRA, and the equation receives a slight tweak:
$h = Wx + BAx$ where $BAx$ is $\Delta W$. What’s notable is that gradients are only computed for matrice A and B. As we continue training and updating these matrices, they effectively shape our $\Delta W$. During inference, we maintain the same forward pass, but without the overhead of monitoring the computation graph.
Perhaps the most captivating facet of LoRA is its modularity. By training distinct ‘adapters’ (A,B matrices), we can tailor them for various tasks. This allows us to seamlessly integrate or switch between these adapters during inference, all the while preserving the foundational parameters of the base model. A truly plug-and-play approach!
Conclusion
In today’s rapidly evolving machine learning landscape, the adoption of large models poses both an opportunity and a challenge. While the promise of unparalleled performance beckons, the practical hurdles of deployment, finetuning, and resource efficiency can often seem daunting. Through this blogpost, we’ve delved into the depths of LoRA and its innovative approach to parameter-efficient tuning, illustrating how it sidesteps many of the traditional pitfalls of working with colossal models. The technique’s dual-pronged strategy of integrating modularity with efficiency offers a powerful tool for businesses and researchers alike. By understanding and harnessing tools like LoRA and QLoRA, we not only democratize access to state-of-the-art models but also ensure a sustainable future for machine learning where adaptability and efficiency coexist. As we continue to push the boundaries of what’s possible, it’s innovations like these that will shape the next chapter in our AI-driven future.